这里只是 2023 李宏毅机器学习 HW05 样例代码的中文注释版的分享,下面的内容绝大部分是样例代码,补充了小部分函数的功能解释,没有做函数功能上的修改,是 Simple baseline 版本。
notebook 代码下载: [EN] [ZH]
文章目录
- 作业描述
- 下载和导入需要的包
- 固定随机数种子
- 数据集
- 英-中 对应的语料
- 测试集
- 数据集下载
- 语言
- 预处理文件
- 划分训练/验证集
- 子词单位
- 数据二值化(使用 fairseq)
- 实验配置
- 日志
- CUDA 环境
- 数据导入
- 我们采用了 TranslationTask(来自 fairseq)
- 数据集迭代器
- 模型架构
- 编码器
- 注意力
- 解码器
- Seq2Seq
- 模型初始化
- 架构相关配置
- 优化
- 损失(Loss): Label Smoothing Regularization
- 优化器: Adam + 学习率调度
- 调度可视化
- 训练过程
- 训练
- 验证 & 推测
- 保存和加载模型权重
- Main
- 训练循环
- Submission
- 确定用于生成 submission 的模型权重
- 生成预测
- Back-translation
- 训练一个 backward translation 模型
- 用后向模型生成人造数据
- 下载单语言数据
- TODO: 清洗语料
- TODO: 子词单位
- 二值化
- TODO: 用后向模型生成人造数据
- TODO: 创建新的数据集
- References
作业描述
-
英译中(繁体)
- 输入: an English sentence (e.g. tom is a student .)
- 输出: the Chinese translation (e.g. 湯姆 是 個 學生 。)
-
TODO
- 训练一个 seq2seq 的简单的 RNN 模型来完成翻译
- 转变模型架构为 transformer,提升性能
- 使用 Back-translation 进一步提升性能
!nvidia-smi
下载和导入需要的包
!pip install 'torch>=1.6.0' editdistance matplotlib sacrebleu sacremoses sentencepiece tqdm wandb
!pip install --upgrade jupyter ipywidgets
!git clone https://github.com/pytorch/fairseq.git
!cd fairseq && git checkout 3f6ba43
!pip install --upgrade ./fairseq/
import sys
import pdb
import pprint
import logging
import os
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import data
import numpy as np
import tqdm.auto as tqdm
from pathlib import Path
from argparse import Namespace
from fairseq import utils
import matplotlib.pyplot as plt
固定随机数种子
seed = 33
random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
数据集
英-中 对应的语料
- TED2020
- 原始: 400,726 (句子)
- 处理后: 394,052 (句子)
测试集
- 大小: 4,000 (句子)
- 没有提供中文的翻译。(.zh)文件是伪翻译,其中每一行是’。’
数据集下载
data_dir = './DATA/rawdata'
dataset_name = 'ted2020'
urls = (
"https://github.com/figisiwirf/ml2023-hw5-dataset/releases/download/v1.0.1/ml2023.hw5.data.tgz",
"https://github.com/figisiwirf/ml2023-hw5-dataset/releases/download/v1.0.1/ml2023.hw5.test.tgz"
)
file_names = (
'ted2020.tgz', # train & dev
'test.tgz', # test
)
prefix = Path(data_dir).absolute() / dataset_name
prefix.mkdir(parents=True, exist_ok=True)
for u, f in zip(urls, file_names):
path = prefix/f
if not path.exists():
!wget {u} -O {path}
if path.suffix == ".tgz":
!tar -xvf {path} -C {prefix}
elif path.suffix == ".zip":
!unzip -o {path} -d {prefix}
!mv {prefix/'raw.en'} {prefix/'train_dev.raw.en'}
!mv {prefix/'raw.zh'} {prefix/'train_dev.raw.zh'}
!mv {prefix/'test.en'} {prefix/'test.raw.en'}
!mv {prefix/'test.zh'} {prefix/'test.raw.zh'}
语言
src_lang = 'en'
tgt_lang = 'zh'
data_prefix = f'{prefix}/train_dev.raw'
test_prefix = f'{prefix}/test.raw'
!head {data_prefix+'.'+src_lang} -n 5
!head {data_prefix+'.'+tgt_lang} -n 5
预处理文件
- strQ2B(): 将全角字符转变为半角字符
- clean_s(): 清洗文本,将逗号/破折号/空格等字符删除
- len_s(): 返回文本长度
- clean_corpus: 使用上面的函数对指定的文本文件进行清洗
import re
def strQ2B(ustring):
"""Full width -> half width"""
# reference:https://ithelp.ithome.com.tw/articles/10233122
ss = []
for s in ustring:
rstring = ""
for uchar in s:
inside_code = ord(uchar)
if inside_code == 12288: # Full width space: direct conversion
inside_code = 32
elif (inside_code >= 65281 and inside_code <= 65374): # Full width chars (except space) conversion
inside_code -= 65248
rstring += chr(inside_code)
ss.append(rstring)
return ''.join(ss)
def clean_s(s, lang):
if lang == 'en':
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace('-', '') # remove '-'
s = re.sub('([.,;!?()\"])', r' \1 ', s) # keep punctuation
elif lang == 'zh':
s = strQ2B(s) # Q2B
s = re.sub(r"\([^()]*\)", "", s) # remove ([text])
s = s.replace(' ', '')
s = s.replace('—', '')
s = s.replace('“', '"')
s = s.replace('”', '"')
s = s.replace('_', '')
s = re.sub('([。,;!?()\"~「」])', r' \1 ', s) # keep punctuation
s = ' '.join(s.strip().split())
return s
def len_s(s, lang):
if lang == 'zh':
return len(s)
return len(s.split())
def clean_corpus(prefix, l1, l2, ratio=9, max_len=1000, min_len=1):
if Path(f'{prefix}.clean.{l1}').exists() and Path(f'{prefix}.clean.{l2}').exists():
print(f'{prefix}.clean.{l1} & {l2} exists. skipping clean.')
return
with open(f'{prefix}.{l1}', 'r') as l1_in_f:
with open(f'{prefix}.{l2}', 'r') as l2_in_f:
with open(f'{prefix}.clean.{l1}', 'w') as l1_out_f:
with open(f'{prefix}.clean.{l2}', 'w') as l2_out_f:
for s1 in l1_in_f:
s1 = s1.strip()
s2 = l2_in_f.readline().strip()
s1 = clean_s(s1, l1)
s2 = clean_s(s2, l2)
s1_len = len_s(s1, l1)
s2_len = len_s(s2, l2)
if min_len > 0: # remove short sentence
if s1_len < min_len or s2_len < min_len:
continue
if max_len > 0: # remove long sentence
if s1_len > max_len or s2_len > max_len:
continue
if ratio > 0: # remove by ratio of length
if s1_len/s2_len > ratio or s2_len/s1_len > ratio:
continue
print(s1, file=l1_out_f)
print(s2, file=l2_out_f)
clean_corpus(data_prefix, src_lang, tgt_lang)
clean_corpus(test_prefix, src_lang, tgt_lang, ratio=-1, min_len=-1, max_len=-1)
!head {data_prefix+'.clean.'+src_lang} -n 5
!head {data_prefix+'.clean.'+tgt_lang} -n 5
划分训练/验证集
valid_ratio = 0.01 # 3000~4000 就够用了
train_ratio = 1 - valid_ratio
if (prefix/f'train.clean.{src_lang}').exists() \
and (prefix/f'train.clean.{tgt_lang}').exists() \
and (prefix/f'valid.clean.{src_lang}').exists() \
and (prefix/f'valid.clean.{tgt_lang}').exists():
print(f'train/valid splits exists. skipping split.')
else:
line_num = sum(1 for line in open(f'{data_prefix}.clean.{src_lang}'))
labels = list(range(line_num))
random.shuffle(labels)
for lang in [src_lang, tgt_lang]:
train_f = open(os.path.join(data_dir, dataset_name, f'train.clean.{lang}'), 'w')
valid_f = open(os.path.join(data_dir, dataset_name, f'valid.clean.{lang}'), 'w')
count = 0
for line in open(f'{data_prefix}.clean.{lang}', 'r'):
if labels[count]/line_num < train_ratio:
train_f.write(line)
else:
valid_f.write(line)
count += 1
train_f.close()
valid_f.close()
子词单位
不在词表中的单词(OOV)是机器翻译面临的主要问题。这个问题可以通过使用子词(subword)作为基本单位来缓解
- 我们将使用 sentencepiece 包
- 选择 unigram 或者 byte-pair encoding (BPE) 算法
import sentencepiece as spm
vocab_size = 8000
if (prefix/f'spm{vocab_size}.model').exists():
print(f'{prefix}/spm{vocab_size}.model exists. skipping spm_train.')
else:
spm.SentencePieceTrainer.train(
input=','.join([f'{prefix}/train.clean.{src_lang}',
f'{prefix}/valid.clean.{src_lang}',
f'{prefix}/train.clean.{tgt_lang}',
f'{prefix}/valid.clean.{tgt_lang}']),
model_prefix=prefix/f'spm{vocab_size}',
vocab_size=vocab_size,
character_coverage=1,
model_type='unigram', # 'bpe' works as well
input_sentence_size=1e6,
shuffle_input_sentence=True,
normalization_rule_name='nmt_nfkc_cf',
)
spm_model = spm.SentencePieceProcessor(model_file=str(prefix/f'spm{vocab_size}.model'))
in_tag = {
'train': 'train.clean',
'valid': 'valid.clean',
'test': 'test.raw.clean',
}
for split in ['train', 'valid', 'test']:
for lang in [src_lang, tgt_lang]:
out_path = prefix/f'{split}.{lang}'
if out_path.exists():
print(f"{out_path} exists. skipping spm_encode.")
else:
with open(prefix/f'{split}.{lang}', 'w') as out_f:
with open(prefix/f'{in_tag[split]}.{lang}', 'r') as in_f:
for line in in_f:
line = line.strip()
tok = spm_model.encode(line, out_type=str)
print(' '.join(tok), file=out_f)
!head {data_dir+'/'+dataset_name+'/train.'+src_lang} -n 5
!head {data_dir+'/'+dataset_name+'/train.'+tgt_lang} -n 5
数据二值化(使用 fairseq)
配对源语言和目标语言的文件。
如果没有对应的文件,就生成伪配对来方便二值化。
binpath = Path('./DATA/data-bin', dataset_name)
if binpath.exists():
print(binpath, "exists, will not overwrite!")
else:
!python -m fairseq_cli.preprocess \
--source-lang {src_lang}\
--target-lang {tgt_lang}\
--trainpref {prefix/'train'}\
--validpref {prefix/'valid'}\
--testpref {prefix/'test'}\
--destdir {binpath}\
--joined-dictionary\
--workers 2
实验配置
config = Namespace(
datadir = "./DATA/data-bin/ted2020",
savedir = "./checkpoints/rnn",
source_lang = src_lang,
target_lang = tgt_lang,
# 设置取数据和处理数据时 cpu 的线程数
num_workers=2,
# batch size 按照 token 数量来计算。梯度累积可以增加有效的 batch size。
max_tokens=8192,
accum_steps=2,
# 学习率通过 Noam 调度器进行计算。你可以修改lr_factor来调整最大的学习率。
lr_factor=2.,
lr_warmup=4000,
# 梯度裁剪可以缓解梯度爆炸
clip_norm=1.0,
# 训练的最大轮数
max_epoch=15,
start_epoch=1,
# 集束搜索中的 beam size
beam=5,
# 生成的序列的最大长度为 ax + b,其中 x 是源长度
max_len_a=1.2,
max_len_b=10,
# 解码时,通过去除 sentencepiece 符号和 jieba 分词来后处理句子。
post_process = "sentencepiece",
# 检查点
keep_last_epochs=5,
resume=None, # if resume 则根据 checkpoint name 进行恢复(文件保存在 config.savedir 下)
# 日志记录
use_wandb=False,
)
日志
- logging 包用于记录普通的信息
- wandb 记录训练过程中的损失/bleu等
logging.basicConfig(
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level="INFO", # "DEBUG" "WARNING" "ERROR"
stream=sys.stdout,
)
proj = "hw5.seq2seq"
logger = logging.getLogger(proj)
if config.use_wandb:
import wandb
wandb.init(project=proj, name=Path(config.savedir).stem, config=config)
CUDA 环境
cuda_env = utils.CudaEnvironment()
utils.CudaEnvironment.pretty_print_cuda_env_list([cuda_env])
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
数据导入
我们采用了 TranslationTask(来自 fairseq)
- 用于加载上面创建的二值化数据
- 实现数据迭代器(dataloader)
- 内置的 task.source_dictionary 和 task.target_dictionary 也很有用
- 实现集束搜索解码器
from fairseq.tasks.translation import TranslationConfig, TranslationTask
## setup task
task_cfg = TranslationConfig(
data=config.datadir,
source_lang=config.source_lang,
target_lang=config.target_lang,
train_subset="train",
required_seq_len_multiple=8,
dataset_impl="mmap",
upsample_primary=1,
)
task = TranslationTask.setup_task(task_cfg)
logger.info("loading data for epoch 1")
task.load_dataset(split="train", epoch=1, combine=True) # combine if you have back-translation data.
task.load_dataset(split="valid", epoch=1)
sample = task.dataset("valid")[1]
pprint.pprint(sample)
pprint.pprint(
"Source: " + \
task.source_dictionary.string(
sample['source'],
config.post_process,
)
)
pprint.pprint(
"Target: " + \
task.target_dictionary.string(
sample['target'],
config.post_process,
)
)
数据集迭代器
- 控制每个 batch 不超过 N 个 token,这样可以优化 GPU 内存效率
- 在每个 epoch 都对训练集进行随机打乱
- 忽略超过最大长度的句子
- 将一个 batch 中的所有句子填充到相同的长度,这样可以利用 GPU 进行并行计算
- 添加 eos 并移动一个 token
- teacher forcing 技术: 为了训练模型根据前缀预测下一个 token,我们将移动后的目标序列作为解码器的输入。
- 一般来说,在目标前面加上 bos 就可以了(如下图所示)
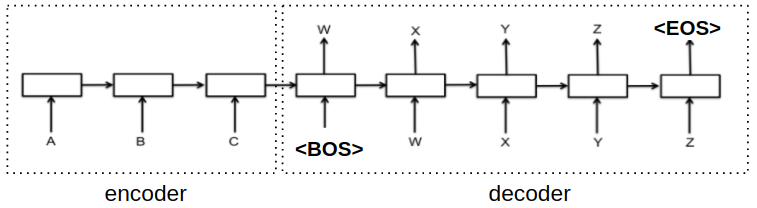
- 但是在 fairseq 中,这是通过将 eos token 移动到开头来实现的。在实验上,这个操作拥有相同的效果。例如:
# 目标输出(target)和解码器输入(prev_output_tokens): eos = 2 target = 419, 711, 238, 888, 792, 60, 968, 8, 2 prev_output_tokens = 2, 419, 711, 238, 888, 792, 60, 968, 8
def load_data_iterator(task, split, epoch=1, max_tokens=4000, num_workers=1, cached=True):
batch_iterator = task.get_batch_iterator(
dataset=task.dataset(split),
max_tokens=max_tokens,
max_sentences=None,
max_positions=utils.resolve_max_positions(
task.max_positions(),
max_tokens,
),
ignore_invalid_inputs=True,
seed=seed,
num_workers=num_workers,
epoch=epoch,
disable_iterator_cache=not cached,
# 如果设置为 False(cached=True),可以加快训练速度。
# 但是,如果设置为 False,那么在第一次调用这个方法之后,再改变 max_tokens就没有效果了。
)
return batch_iterator
demo_epoch_obj = load_data_iterator(task, "valid", epoch=1, max_tokens=20, num_workers=1, cached=False)
demo_iter = demo_epoch_obj.next_epoch_itr(shuffle=True)
sample = next(demo_iter)
sample
- each batch is a python dict, with string key and Tensor value. Contents are described below:
batch = {
"id": id, # id for each example
"nsentences": len(samples), # batch size (sentences)
"ntokens": ntokens, # batch size (tokens)
"net_input": {
"src_tokens": src_tokens, # sequence in source language
"src_lengths": src_lengths, # sequence length of each example before padding
"prev_output_tokens": prev_output_tokens, # right shifted target, as mentioned above.
},
"target": target, # target sequence
}
模型架构
- 我们再次继承 fairseq 的编码器、解码器和模型,以便在测试阶段可以直接利用 fairseq 的集束搜索解码器。
from fairseq.models import (
FairseqEncoder,
FairseqIncrementalDecoder,
FairseqEncoderDecoderModel
)
编码器
-
编码器(Encoder)是一个循环神经网络(RNN)或者 Transformer 中的编码器。下面的描述是针对 RNN 的。对于每一个输入的 token,编码器会生成一个输出向量和一个隐藏状态向量,并且将隐藏状态向量传递给下一步。换句话说,编码器顺序地读入输入序列,并且在每一个时间步输出一个单独的向量,然后在最后一个时间步输出最终的隐藏状态,或者称为内容向量(content vector)。
-
参数:
- args
- encoder_embed_dim: 嵌入的维度,将 one-hot 向量压缩到固定的维度,实现降维的效果
- encoder_ffn_embed_dim: 隐藏状态和输出向量的维度
- encoder_layers: RNN 编码器的层数
- dropout 确定了一个神经元的激活值被设为 0 的概率,用于防止过拟合。通常这个参数在训练时使用,在测试时移除
- dictionary: fairseq 提供的字典。它用于获取填充索引,进而得到编码器的填充掩码(encoder padding mask)
- embed_tokens: 一个 token embedding 的实例(nn.Embedding)
- args
-
Inputs:
- src_tokens: 一个表示英语的整数序列,例如: 1, 28, 29, 205, 2
-
Outputs:
- outputs: RNN 在每个时间步的输出,可以由注意力机制(Attention)进一步处理
- final_hiddens: 每个时间步的隐藏状态,会被传递给解码器(decoder)进行解码
- encoder_padding_mask: 这个参数告诉解码器哪些位置要忽略
class RNNEncoder(FairseqEncoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
self.embed_dim = args.encoder_embed_dim
self.hidden_dim = args.encoder_ffn_embed_dim
self.num_layers = args.encoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=True
)
self.dropout_out_module = nn.Dropout(args.dropout)
self.padding_idx = dictionary.pad()
def combine_bidir(self, outs, bsz: int):
out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()
return out.view(self.num_layers, bsz, -1)
def forward(self, src_tokens, **unused):
bsz, seqlen = src_tokens.size()
# 获取 embeddings
x = self.embed_tokens(src_tokens)
x = self.dropout_in_module(x)
# B x T x C -> T x B x C
x = x.transpose(0, 1)
# 经过双向的 RNN
h0 = x.new_zeros(2 * self.num_layers, bsz, self.hidden_dim)
x, final_hiddens = self.rnn(x, h0)
outputs = self.dropout_out_module(x)
# outputs = [sequence len, batch size, hid dim * directions]
# hidden = [num_layers * directions, batch size , hid dim]
# 由于编码器是双向的,我们需要将两个方向的隐藏状态连接起来
final_hiddens = self.combine_bidir(final_hiddens, bsz)
# hidden = [num_layers x batch x num_directions*hidden]
encoder_padding_mask = src_tokens.eq(self.padding_idx).t()
return tuple(
(
outputs, # seq_len x batch x hidden
final_hiddens, # num_layers x batch x num_directions*hidden
encoder_padding_mask, # seq_len x batch
)
)
def reorder_encoder_out(self, encoder_out, new_order):
# 这个被用于 fairseq 的集束搜索。它的具体细节和原因并不重要。
return tuple(
(
encoder_out[0].index_select(1, new_order),
encoder_out[1].index_select(1, new_order),
encoder_out[2].index_select(1, new_order),
)
)
注意力
-
当输入序列很长时,单独的“内容向量”就不能准确地表示整个序列,注意力机制可以为解码器提供更多信息。
-
根据当前时间步的解码器embeddings,将编码器输出与解码器 embeddings 进行匹配,确定相关性,然后将编码器输出按相关性加权求和作为解码器 RNN 的输入。
-
常见的注意力实现使用神经网络/点积作为 query(解码器 embeddings)和 key(编码器输出)之间的相关性,然后用 softmax 得到一个分布,最后用该分布对 value(编码器输出)进行加权求和。
-
参数:
- input_embed_dim: key 的维度,应该是解码器中用于 attend 其他向量的向量的维度
- source_embed_dim: query 的维度,应该是被 attend 的向量(编码器输出)的维度
- output_embed_dim: value 的维度,应该是 after attention 的向量的维度,符合下一层的期望,
-
Inputs:
- inputs: key, 用于 attend 其他向量
- encoder_outputs: query/value, 被 attend 的向量
- encoder_padding_mask: 这个告诉解码器应该忽略那些位置
-
Outputs:
- output: attention 后的上下文向量
- attention score: attention 的分数
class AttentionLayer(nn.Module):
def __init__(self, input_embed_dim, source_embed_dim, output_embed_dim, bias=False):
super().__init__()
self.input_proj = nn.Linear(input_embed_dim, source_embed_dim, bias=bias)
self.output_proj = nn.Linear(
input_embed_dim + source_embed_dim, output_embed_dim, bias=bias
)
def forward(self, inputs, encoder_outputs, encoder_padding_mask):
# inputs: T, B, dim
# encoder_outputs: S x B x dim
# padding mask: S x B
# 将所有的输入的维度改为 batch first
inputs = inputs.transpose(1,0) # B, T, dim
encoder_outputs = encoder_outputs.transpose(1,0) # B, S, dim
encoder_padding_mask = encoder_padding_mask.transpose(1,0) # B, S
# 投影到 encoder_outputs 的维度
x = self.input_proj(inputs)
# 计算 attention
# (B, T, dim) x (B, dim, S) = (B, T, S)
attn_scores = torch.bmm(x, encoder_outputs.transpose(1,2))
# 取消与 padding 相对应的位置的 attention
if encoder_padding_mask is not None:
# leveraging broadcast B, S -> (B, 1, S)
encoder_padding_mask = encoder_padding_mask.unsqueeze(1)
attn_scores = (
attn_scores.float()
.masked_fill_(encoder_padding_mask, float("-inf"))
.type_as(attn_scores)
) # FP16 support: cast to float and back
# 在与源序列对应的维度上进行 softmax
attn_scores = F.softmax(attn_scores, dim=-1)
# shape (B, T, S) x (B, S, dim) = (B, T, dim) 加权求和
x = torch.bmm(attn_scores, encoder_outputs)
# (B, T, dim)
x = torch.cat((x, inputs), dim=-1)
x = torch.tanh(self.output_proj(x)) # concat + linear + tanh
# restore shape (B, T, dim) -> (T, B, dim)
return x.transpose(1,0), attn_scores
解码器
- 解码器的隐藏状态将由编码器的最终隐藏状态(the content vector)初始化
- 同时,解码器会根据当前时间步的输入(前一时间步的输出)改变其隐藏状态,并生成一个输出
- 注意力机制可以提高性能
- seq2seq 的步骤是在解码器中实现的,这样以后 Seq2Seq 类可以接受 RNN 和 Transformer,而不需要进一步修改。
- 参数:
- args
- decoder_embed_dim: 解码器嵌入的维度,类似于 encoder_embed_dim
- decoder_ffn_embed_dim: 解码器 RNN 隐藏状态的维度,类似于 encoder_ffn_embed_dim
- decoder_layers: RNN 解码器的层数
- share_decoder_input_output_embed: 通常,解码器的投影矩阵会与解码器输入 embeddings 共享权重
- dictionary: fairseq 提供的字典
- embed_tokens: 一个 token embedding 的实例(nn.Embedding)
- args
- 输入:
- prev_output_tokens: 表示右移目标的整数序列,例如: 1, 28, 29, 205, 2
- encoder_out: 编码器的输出
- incremental_state: 为了加速测试时的解码,我们会保存每个时间步的隐藏状态。详见forward()。
- 输出:
- outputs: 解码器在每个时间步的输出的对数(softmax之前)
- extra: 未使用
class RNNDecoder(FairseqIncrementalDecoder):
def __init__(self, args, dictionary, embed_tokens):
super().__init__(dictionary)
self.embed_tokens = embed_tokens
assert args.decoder_layers == args.encoder_layers, f"""seq2seq rnn requires that encoder
and decoder have same layers of rnn. got: {args.encoder_layers, args.decoder_layers}"""
assert args.decoder_ffn_embed_dim == args.encoder_ffn_embed_dim*2, f"""seq2seq-rnn requires
that decoder hidden to be 2*encoder hidden dim. got: {args.decoder_ffn_embed_dim, args.encoder_ffn_embed_dim*2}"""
self.embed_dim = args.decoder_embed_dim
self.hidden_dim = args.decoder_ffn_embed_dim
self.num_layers = args.decoder_layers
self.dropout_in_module = nn.Dropout(args.dropout)
self.rnn = nn.GRU(
self.embed_dim,
self.hidden_dim,
self.num_layers,
dropout=args.dropout,
batch_first=False,
bidirectional=False
)
self.attention = AttentionLayer(
self.embed_dim, self.hidden_dim, self.embed_dim, bias=False
)
# self.attention = None
self.dropout_out_module = nn.Dropout(args.dropout)
if self.hidden_dim != self.embed_dim:
self.project_out_dim = nn.Linear(self.hidden_dim, self.embed_dim)
else:
self.project_out_dim = None
if args.share_decoder_input_output_embed:
self.output_projection = nn.Linear(
self.embed_tokens.weight.shape[1],
self.embed_tokens.weight.shape[0],
bias=False,
)
self.output_projection.weight = self.embed_tokens.weight
else:
self.output_projection = nn.Linear(
self.output_embed_dim, len(dictionary), bias=False
)
nn.init.normal_(
self.output_projection.weight, mean=0, std=self.output_embed_dim ** -0.5
)
def forward(self, prev_output_tokens, encoder_out, incremental_state=None, **unused):
# 从编码器中提取输出
encoder_outputs, encoder_hiddens, encoder_padding_mask = encoder_out
# outputs: seq_len x batch x num_directions*hidden
# encoder_hiddens: num_layers x batch x num_directions*encoder_hidden
# padding_mask: seq_len x batch
if incremental_state is not None and len(incremental_state) > 0:
# 如果保留了上一个时间步的信息,可以从那里继续,而不是从bos开始
prev_output_tokens = prev_output_tokens[:, -1:]
cache_state = self.get_incremental_state(incremental_state, "cached_state")
prev_hiddens = cache_state["prev_hiddens"]
else:
# 增量状态不存在,要么是训练时,要么是测试时的第一个时间步
# 为seq2seq做准备:将编码器的隐藏状态传递给解码器的隐藏状态
prev_hiddens = encoder_hiddens
bsz, seqlen = prev_output_tokens.size()
# embed tokens
x = self.embed_tokens(prev_output_tokens)
x = self.dropout_in_module(x)
# B x T x C -> T x B x C
x = x.transpose(0, 1)
# decoder-to-encoder attention
if self.attention is not None:
x, attn = self.attention(x, encoder_outputs, encoder_padding_mask)
# 经过单向的 RNN
x, final_hiddens = self.rnn(x, prev_hiddens)
# outputs = [sequence len, batch size, hid dim]
# hidden = [num_layers * directions, batch size , hid dim]
x = self.dropout_out_module(x)
# 投影到 embedding size(如果隐藏状态与 embedding size 不同,并且 share_embedding 为True
# 就需要做一个额外的投影)
if self.project_out_dim != None:
x = self.project_out_dim(x)
# 投影到 vocab size
x = self.output_projection(x)
# T x B x C -> B x T x C
x = x.transpose(1, 0)
# if incremental, 则记录当前时间步的隐藏状态,在下一个时间步恢复
cache_state = {
"prev_hiddens": final_hiddens,
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return x, None
def reorder_incremental_state(self, incremental_state, new_order):
# 这个被用于 fairseq 的集束搜索。它的具体细节和原因并不重要。
cache_state = self.get_incremental_state(incremental_state, "cached_state")
prev_hiddens = cache_state["prev_hiddens"]
prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens]
cache_state = {
"prev_hiddens": torch.stack(prev_hiddens),
}
self.set_incremental_state(incremental_state, "cached_state", cache_state)
return
Seq2Seq
- 由编码器和解码器组成
- 接收输入并传递给编码器
- 将编码器的输出传递给解码器
- 解码器会根据前一时间步的输出以及编码器的输出进行解码
- 解码完成后,返回解码器的输出
class Seq2Seq(FairseqEncoderDecoderModel):
def __init__(self, args, encoder, decoder):
super().__init__(encoder, decoder)
self.args = args
def forward(
self,
src_tokens,
src_lengths,
prev_output_tokens,
return_all_hiddens: bool = True,
):
"""
Run the forward pass for an encoder-decoder model.
"""
encoder_out = self.encoder(
src_tokens, src_lengths=src_lengths, return_all_hiddens=return_all_hiddens
)
logits, extra = self.decoder(
prev_output_tokens,
encoder_out=encoder_out,
src_lengths=src_lengths,
return_all_hiddens=return_all_hiddens,
)
return logits, extra
模型初始化
# # 提示: transformer 架构
from fairseq.models.transformer import (
TransformerEncoder,
TransformerDecoder,
)
def build_model(args, task):
""" build a model instance based on hyperparameters """
src_dict, tgt_dict = task.source_dictionary, task.target_dictionary
# token embeddings
encoder_embed_tokens = nn.Embedding(len(src_dict), args.encoder_embed_dim, src_dict.pad())
decoder_embed_tokens = nn.Embedding(len(tgt_dict), args.decoder_embed_dim, tgt_dict.pad())
# encoder decoder
# 提示: TODO: 转变为 TransformerEncoder & TransformerDecoder
encoder = RNNEncoder(args, src_dict, encoder_embed_tokens)
decoder = RNNDecoder(args, tgt_dict, decoder_embed_tokens)
# encoder = TransformerEncoder(args, src_dict, encoder_embed_tokens)
# decoder = TransformerDecoder(args, tgt_dict, decoder_embed_tokens)
# 序列到序列的模型
model = Seq2Seq(args, encoder, decoder)
# 初始化 seq2seq 模型很重要, 需要额外的处理
def init_params(module):
from fairseq.modules import MultiheadAttention
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.bias is not None:
module.bias.data.zero_()
if isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=0.02)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
if isinstance(module, MultiheadAttention):
module.q_proj.weight.data.normal_(mean=0.0, std=0.02)
module.k_proj.weight.data.normal_(mean=0.0, std=0.02)
module.v_proj.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.RNNBase):
for name, param in module.named_parameters():
if "weight" in name or "bias" in name:
param.data.uniform_(-0.1, 0.1)
# 权重初始化
model.apply(init_params)
return model
架构相关配置
为了达成 strong baseline,请参考 Attention is all you need 中表 3 中 transformer-base 的超参数
arch_args = Namespace(
encoder_embed_dim=256,
encoder_ffn_embed_dim=512,
encoder_layers=1,
decoder_embed_dim=256,
decoder_ffn_embed_dim=1024,
decoder_layers=1,
share_decoder_input_output_embed=True,
dropout=0.3,
)
# 提示: 这些是 Transformer 的参数补丁
def add_transformer_args(args):
args.encoder_attention_heads=4
args.encoder_normalize_before=True
args.decoder_attention_heads=4
args.decoder_normalize_before=True
args.activation_fn="relu"
args.max_source_positions=1024
args.max_target_positions=1024
# Transformer 默认参数的补丁(未在上面设置的参数)
from fairseq.models.transformer import base_architecture
base_architecture(arch_args)
# add_transformer_args(arch_args)
if config.use_wandb:
wandb.config.update(vars(arch_args))
model = build_model(arch_args, task)
logger.info(model)
优化
损失(Loss): Label Smoothing Regularization
- 让模型学习生成更少集中的分布,防止过度自信
- 有时候正确答案可能不是唯一的。因此,在计算损失时,我们为错误标签保留一些概率。
- 避免过拟合
代码 source
class LabelSmoothedCrossEntropyCriterion(nn.Module):
def __init__(self, smoothing, ignore_index=None, reduce=True):
super().__init__()
self.smoothing = smoothing
self.ignore_index = ignore_index
self.reduce = reduce
def forward(self, lprobs, target):
if target.dim() == lprobs.dim() - 1:
target = target.unsqueeze(-1)
# nll: Negative log likelihood 负对数似然,当目标是 one-hot 时的交叉熵。下一行代码等同于F.nll_loss
nll_loss = -lprobs.gather(dim=-1, index=target)
# 保留一些其他标签的概率,这样在计算交叉熵的时候相当于对所有标签的对数概率求和
smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
if self.ignore_index is not None:
pad_mask = target.eq(self.ignore_index)
nll_loss.masked_fill_(pad_mask, 0.0)
smooth_loss.masked_fill_(pad_mask, 0.0)
else:
nll_loss = nll_loss.squeeze(-1)
smooth_loss = smooth_loss.squeeze(-1)
if self.reduce:
nll_loss = nll_loss.sum()
smooth_loss = smooth_loss.sum()
# 在计算交叉熵的时候,增加其他标签的损失
eps_i = self.smoothing / lprobs.size(-1)
loss = (1.0 - self.smoothing) * nll_loss + eps_i * smooth_loss
return loss
# 通常来说,0.1 已经足够好了
criterion = LabelSmoothedCrossEntropyCriterion(
smoothing=0.1,
ignore_index=task.target_dictionary.pad(),
)
优化器: Adam + 学习率调度
在训练 Transformer 时,平方根倒数调度(Inverse square root scheduling)对于稳定性非常重要,在后面也用于RNN。
根据以下公式更新学习率,第一阶段线性增加,然后按时间步的平方根倒数成比例衰减。
l
r
a
t
e
=
d
model
−
0.5
⋅
min
(
s
t
e
p
_
n
u
m
−
0.5
,
s
t
e
p
_
n
u
m
⋅
w
a
r
m
u
p
_
s
t
e
p
s
−
1.5
)
lrate = d_{\text{model}}^{-0.5}\cdot\min({step\_num}^{-0.5},{step\_num}\cdot{warmup\_steps}^{-1.5})
lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)
def get_rate(d_model, step_num, warmup_step):
# TODO: 将 lr 从常数修改为上面显示的公式
lr = 0.001
return lr
class NoamOpt:
"Optim 包装,用于实现 rate"
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
@property
def param_groups(self):
return self.optimizer.param_groups
def multiply_grads(self, c):
"""将梯度乘以常数*c*."""
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.data.mul_(c)
def step(self):
"更新参数和 rate"
self._step += 1
rate = self.rate()
for p in self.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"实现上面的 `lrate`"
if step is None:
step = self._step
return 0 if not step else self.factor * get_rate(self.model_size, step, self.warmup)
调度可视化
optimizer = NoamOpt(
model_size=arch_args.encoder_embed_dim,
factor=config.lr_factor,
warmup=config.lr_warmup,
optimizer=torch.optim.AdamW(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9, weight_decay=0.0001))
plt.plot(np.arange(1, 100000), [optimizer.rate(i) for i in range(1, 100000)])
plt.legend([f"{optimizer.model_size}:{optimizer.warmup}"])
None
训练过程
训练
from fairseq.data import iterators
from torch.cuda.amp import GradScaler, autocast
def train_one_epoch(epoch_itr, model, task, criterion, optimizer, accum_steps=1):
itr = epoch_itr.next_epoch_itr(shuffle=True)
itr = iterators.GroupedIterator(itr, accum_steps) # 梯度累积:每 accum_steps 个样本更新一次
stats = {"loss": []}
scaler = GradScaler() # 自动混合精度(amp)
model.train()
progress = tqdm.tqdm(itr, desc=f"train epoch {epoch_itr.epoch}", leave=False)
for samples in progress:
model.zero_grad()
accum_loss = 0
sample_size = 0
# 梯度累积:每 accum_steps 个样本更新一次
for i, sample in enumerate(samples):
if i == 1:
# 在第一步之后清空 CUDA 缓存可以减少 OOM(out of memory)的机会
torch.cuda.empty_cache()
sample = utils.move_to_cuda(sample, device=device)
target = sample["target"]
sample_size_i = sample["ntokens"]
sample_size += sample_size_i
# 混合精度训练
with autocast():
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1))
# 日志记录
accum_loss += loss.item()
# 反向传播
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
optimizer.multiply_grads(1 / (sample_size or 1.0)) # (sample_size or 1.0) 处理零梯度的情况
gnorm = nn.utils.clip_grad_norm_(model.parameters(), config.clip_norm) # 梯度裁剪防止梯度爆炸
scaler.step(optimizer)
scaler.update()
# 日志记录
loss_print = accum_loss/sample_size
stats["loss"].append(loss_print)
progress.set_postfix(loss=loss_print)
if config.use_wandb:
wandb.log({
"train/loss": loss_print,
"train/grad_norm": gnorm.item(),
"train/lr": optimizer.rate(),
"train/sample_size": sample_size,
})
loss_print = np.mean(stats["loss"])
logger.info(f"training loss: {loss_print:.4f}")
return stats
验证 & 推测
为了防止过拟合,每个训练周期都需要进行验证,以验证模型在未见过的数据上的性能。
- 该过程与训练基本相同,只是多了一个推测步骤。
- 在验证后,我们可以保存模型的权重。
仅凭验证损失无法描述模型的实际性能
- 基于当前模型直接生成翻译假设,然后使用参考翻译计算BLEU
- 我们也可以手动检查假设的质量
- 我们使用 fairseq 的序列生成器进行集束搜索以生成翻译假设。
# fairseq 的集束搜索生成器
# 给定模型和输入序列,通过集束搜索生成翻译假设
sequence_generator = task.build_generator([model], config)
def decode(toks, dictionary):
# 将 Tensor 转换为人类可读的句子
s = dictionary.string(
toks.int().cpu(),
config.post_process,
)
return s if s else "<unk>"
def inference_step(sample, model):
gen_out = sequence_generator.generate([model], sample)
srcs = []
hyps = []
refs = []
for i in range(len(gen_out)):
# 对于每个样本,收集输入、假设和参考,稍后用于计算 BLEU
srcs.append(decode(
utils.strip_pad(sample["net_input"]["src_tokens"][i], task.source_dictionary.pad()),
task.source_dictionary,
))
hyps.append(decode(
gen_out[i][0]["tokens"], # 0 表示使用集束中的最佳假设
task.target_dictionary,
))
refs.append(decode(
utils.strip_pad(sample["target"][i], task.target_dictionary.pad()),
task.target_dictionary,
))
return srcs, hyps, refs
import shutil
import sacrebleu
def validate(model, task, criterion, log_to_wandb=True):
logger.info('begin validation')
itr = load_data_iterator(task, "valid", 1, config.max_tokens, config.num_workers).next_epoch_itr(shuffle=False)
stats = {"loss":[], "bleu": 0, "srcs":[], "hyps":[], "refs":[]}
srcs = []
hyps = []
refs = []
model.eval()
progress = tqdm.tqdm(itr, desc=f"validation", leave=False)
with torch.no_grad():
for i, sample in enumerate(progress):
# 验证损失
sample = utils.move_to_cuda(sample, device=device)
net_output = model.forward(**sample["net_input"])
lprobs = F.log_softmax(net_output[0], -1)
target = sample["target"]
sample_size = sample["ntokens"]
loss = criterion(lprobs.view(-1, lprobs.size(-1)), target.view(-1)) / sample_size
progress.set_postfix(valid_loss=loss.item())
stats["loss"].append(loss)
# 做推测
s, h, r = inference_step(sample, model)
srcs.extend(s)
hyps.extend(h)
refs.extend(r)
tok = 'zh' if task.cfg.target_lang == 'zh' else '13a'
stats["loss"] = torch.stack(stats["loss"]).mean().item()
stats["bleu"] = sacrebleu.corpus_bleu(hyps, [refs], tokenize=tok) # 計算BLEU score
stats["srcs"] = srcs
stats["hyps"] = hyps
stats["refs"] = refs
if config.use_wandb and log_to_wandb:
wandb.log({
"valid/loss": stats["loss"],
"valid/bleu": stats["bleu"].score,
}, commit=False)
showid = np.random.randint(len(hyps))
logger.info("example source: " + srcs[showid])
logger.info("example hypothesis: " + hyps[showid])
logger.info("example reference: " + refs[showid])
# 显示 bleu 结果
logger.info(f"validation loss:\t{stats['loss']:.4f}")
logger.info(stats["bleu"].format())
return stats
保存和加载模型权重
def validate_and_save(model, task, criterion, optimizer, epoch, save=True):
stats = validate(model, task, criterion)
bleu = stats['bleu']
loss = stats['loss']
if save:
# 保存 epoch checkpoints
savedir = Path(config.savedir).absolute()
savedir.mkdir(parents=True, exist_ok=True)
check = {
"model": model.state_dict(),
"stats": {"bleu": bleu.score, "loss": loss},
"optim": {"step": optimizer._step}
}
torch.save(check, savedir/f"checkpoint{epoch}.pt")
shutil.copy(savedir/f"checkpoint{epoch}.pt", savedir/f"checkpoint_last.pt")
logger.info(f"saved epoch checkpoint: {savedir}/checkpoint{epoch}.pt")
# 保存 epoch 样本
with open(savedir/f"samples{epoch}.{config.source_lang}-{config.target_lang}.txt", "w") as f:
for s, h in zip(stats["srcs"], stats["hyps"]):
f.write(f"{s}\t{h}\n")
# 获取最佳的验证 bleu
if getattr(validate_and_save, "best_bleu", 0) < bleu.score:
validate_and_save.best_bleu = bleu.score
torch.save(check, savedir/f"checkpoint_best.pt")
del_file = savedir / f"checkpoint{epoch - config.keep_last_epochs}.pt"
if del_file.exists():
del_file.unlink()
return stats
def try_load_checkpoint(model, optimizer=None, name=None):
name = name if name else "checkpoint_last.pt"
checkpath = Path(config.savedir)/name
if checkpath.exists():
check = torch.load(checkpath)
model.load_state_dict(check["model"])
stats = check["stats"]
step = "unknown"
if optimizer != None:
optimizer._step = step = check["optim"]["step"]
logger.info(f"loaded checkpoint {checkpath}: step={step} loss={stats['loss']} bleu={stats['bleu']}")
else:
logger.info(f"no checkpoints found at {checkpath}!")
Main
训练循环
model = model.to(device=device)
criterion = criterion.to(device=device)
logger.info("task: {}".format(task.__class__.__name__))
logger.info("encoder: {}".format(model.encoder.__class__.__name__))
logger.info("decoder: {}".format(model.decoder.__class__.__name__))
logger.info("criterion: {}".format(criterion.__class__.__name__))
logger.info("optimizer: {}".format(optimizer.__class__.__name__))
logger.info(
"num. model params: {:,} (num. trained: {:,})".format(
sum(p.numel() for p in model.parameters()),
sum(p.numel() for p in model.parameters() if p.requires_grad),
)
)
logger.info(f"max tokens per batch = {config.max_tokens}, accumulate steps = {config.accum_steps}")
epoch_itr = load_data_iterator(task, "train", config.start_epoch, config.max_tokens, config.num_workers)
try_load_checkpoint(model, optimizer, name=config.resume)
while epoch_itr.next_epoch_idx <= config.max_epoch:
# 训练一个 epoch
train_one_epoch(epoch_itr, model, task, criterion, optimizer, config.accum_steps)
stats = validate_and_save(model, task, criterion, optimizer, epoch=epoch_itr.epoch)
logger.info("end of epoch {}".format(epoch_itr.epoch))
epoch_itr = load_data_iterator(task, "train", epoch_itr.next_epoch_idx, config.max_tokens, config.num_workers)
Submission
# 对几个 checkpoints 进行平均可以产生类似于 ensemble 的效果
checkdir=config.savedir
!python ./fairseq/scripts/average_checkpoints.py \
--inputs {checkdir} \
--num-epoch-checkpoints 5 \
--output {checkdir}/avg_last_5_checkpoint.pt
确定用于生成 submission 的模型权重
# checkpoint_last.pt : 最新的 epoch
# checkpoint_best.pt : 最高的验证 BLEU
# avg_last_5_checkpoint.pt: 最近 5 次 epoch 的平均值
try_load_checkpoint(model, name="avg_last_5_checkpoint.pt")
validate(model, task, criterion, log_to_wandb=False)
None
生成预测
def generate_prediction(model, task, split="test", outfile="./prediction.txt"):
task.load_dataset(split=split, epoch=1)
itr = load_data_iterator(task, split, 1, config.max_tokens, config.num_workers).next_epoch_itr(shuffle=False)
idxs = []
hyps = []
model.eval()
progress = tqdm.tqdm(itr, desc=f"prediction")
with torch.no_grad():
for i, sample in enumerate(progress):
# 验证损失
sample = utils.move_to_cuda(sample, device=device)
# 做推测
s, h, r = inference_step(sample, model)
hyps.extend(h)
idxs.extend(list(sample['id']))
# 根据预处理前的顺序进行排序
hyps = [x for _,x in sorted(zip(idxs,hyps))]
with open(outfile, "w") as f:
for h in hyps:
f.write(h+"\n")
generate_prediction(model, task)
raise
Back-translation
训练一个 backward translation 模型
- 将 config 中的 source_lang 和 target_lang 进行切换
- 更改 config 中的 savedir(例如: “./checkpoints/transformer-back”)
- 训练模型
用后向模型生成人造数据
下载单语言数据
mono_dataset_name = 'mono'
mono_prefix = Path(data_dir).absolute() / mono_dataset_name
mono_prefix.mkdir(parents=True, exist_ok=True)
urls = (
"https://github.com/figisiwirf/ml2023-hw5-dataset/releases/download/v1.0.1/ted_zh_corpus.deduped.gz",
)
file_names = (
'ted_zh_corpus.deduped.gz',
)
for u, f in zip(urls, file_names):
path = mono_prefix/f
if not path.exists():
!wget {u} -O {path}
else:
print(f'{f} is exist, skip downloading')
if path.suffix == ".tgz":
!tar -xvf {path} -C {prefix}
elif path.suffix == ".zip":
!unzip -o {path} -d {prefix}
elif path.suffix == ".gz":
!gzip -fkd {path}
TODO: 清洗语料
- 移除太长或者太短的句子
- 统一标点符号
提示: 你可以使用之前定义的 clean_s() 来执行此操作
TODO: 子词单位
使用后向模型的 spm 模型将数据标记为子词单位
提示: spm 模型位于 DATA/raw-data/[dataset]/spm[vocab_num].model
二值化
使用 fairseq 去二值化数据
binpath = Path('./DATA/data-bin', mono_dataset_name)
src_dict_file = './DATA/data-bin/ted2020/dict.en.txt'
tgt_dict_file = src_dict_file
monopref = str(mono_prefix/"mono.tok") # whatever filepath you get after applying subword tokenization
if binpath.exists():
print(binpath, "exists, will not overwrite!")
else:
!python -m fairseq_cli.preprocess\
--source-lang 'zh'\
--target-lang 'en'\
--trainpref {monopref}\
--destdir {binpath}\
--srcdict {src_dict_file}\
--tgtdict {tgt_dict_file}\
--workers 2
TODO: 用后向模型生成人造数据
将二进制化的单语言数据添加到原始数据目录中,并将其命名为 “split_name”
例如: ./DATA/data-bin/ted2020/[split_name].zh-en.[“en”, “zh”].[“bin”, “idx”]
然后你可以使用 ‘generate_prediction(model, task, split=“split_name”)’ 来生成翻译的预测
# 将二进制化的单语言数据添加到原始数据目录中,并将其命名为 "split_name"
# 例如: ./DATA/data-bin/ted2020/\[split_name\].zh-en.\["en", "zh"\].\["bin", "idx"\]
!cp ./DATA/data-bin/mono/train.zh-en.zh.bin ./DATA/data-bin/ted2020/mono.zh-en.zh.bin
!cp ./DATA/data-bin/mono/train.zh-en.zh.idx ./DATA/data-bin/ted2020/mono.zh-en.zh.idx
!cp ./DATA/data-bin/mono/train.zh-en.en.bin ./DATA/data-bin/ted2020/mono.zh-en.en.bin
!cp ./DATA/data-bin/mono/train.zh-en.en.idx ./DATA/data-bin/ted2020/mono.zh-en.en.idx
# hint: 在 split='mono' 上做预测来创建 prediction_file
# generate_prediction( ... ,split=... ,outfile=... )
TODO: 创建新的数据集
- 将预测数据和单语数据结合
- 使用原始的 spm 模型将数据 tokenize 为子词单位
- 使用 fairseq 将数据二值化
# 将 prediction_file (.en) 和 mono.zh (.zh) 结合为新的数据集
#
# 提示: 用 spm 模型 tokenize prediction_file
# spm_model.encode(line, out_type=str)
# 输出: ./DATA/rawdata/mono/mono.tok.en & mono.tok.zh
#
# 提示: 使用 fairseq 再次二值化这两个文件
# binpath = Path('./DATA/data-bin/synthetic')
# src_dict_file = './DATA/data-bin/ted2020/dict.en.txt'
# tgt_dict_file = src_dict_file
# monopref = ./DATA/rawdata/mono/mono.tok # or whatever path after applying subword tokenization, w/o the suffix (.zh/.en)
# if binpath.exists():
# print(binpath, "exists, will not overwrite!")
# else:
# !python -m fairseq_cli.preprocess\
# --source-lang 'zh'\
# --target-lang 'en'\
# --trainpref {monopref}\
# --destdir {binpath}\
# --srcdict {src_dict_file}\
# --tgtdict {tgt_dict_file}\
# --workers 2
# 根据上面准备的所有文件创建一个新的数据集
!cp -r ./DATA/data-bin/ted2020/ ./DATA/data-bin/ted2020_with_mono/
!cp ./DATA/data-bin/synthetic/train.zh-en.zh.bin ./DATA/data-bin/ted2020_with_mono/train1.en-zh.zh.bin
!cp ./DATA/data-bin/synthetic/train.zh-en.zh.idx ./DATA/data-bin/ted2020_with_mono/train1.en-zh.zh.idx
!cp ./DATA/data-bin/synthetic/train.zh-en.en.bin ./DATA/data-bin/ted2020_with_mono/train1.en-zh.en.bin
!cp ./DATA/data-bin/synthetic/train.zh-en.en.idx ./DATA/data-bin/ted2020_with_mono/train1.en-zh.en.idx
创建新数据集 “ted2020_with_mono”
- 修改 config 中的 datadir (“./DATA/data-bin/ted2020_with_mono”)
- 将 config 中的 source_lang 和 target_lang 进行切换 (“en”, “zh”)
- 更改 config 中的 savedir (例如: “./checkpoints/transformer-bt”)
- 训练模型
References
- Ott, M., Edunov, S., Baevski, A., Fan, A., Gross, S., Ng, N., … & Auli, M. (2019, June). fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations) (pp. 48-53).
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017, December). Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 6000-6010).
- Reimers, N., & Gurevych, I. (2020, November). Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
- Tiedemann, J. (2012, May). Parallel Data, Tools and Interfaces in OPUS. In Lrec (Vol. 2012, pp. 2214-2218).
- Kudo, T., & Richardson, J. (2018, November). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 66-71).
- Sennrich, R., Haddow, B., & Birch, A. (2016, August). Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 86-96).
- Edunov, S., Ott, M., Auli, M., & Grangier, D. (2018). Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 489-500).
- https://github.com/ajinkyakulkarni14/TED-Multilingual-Parallel-Corpus
- https://ithelp.ithome.com.tw/articles/10233122
- https://nlp.seas.harvard.edu/2018/04/03/attention.html
- https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/HW05/HW05.ipynb

![[go 反射] 函数](/images/no-images.jpg)